How InstructLab enables accessible model fine-tuning for gen AI
How InstructLab enables accessible model fine-tuning for gen AI

Adapting large language models (LLMs) for specific use cases traditionally requires extensive resources and expertise. While Gartner says more than 80% of enterprises will have deployed generative AI-enabled applications by 2026, the challenge of customizing these models for domain-specific tasks remains significant. InstructLab, an open-source project developed by IBM and Red Hat, aims to address this gap by democratizing LLM tuning. Let’s take a look at how InstructLab enables developers (and domain experts) to enhance and specialize language models efficiently, even on consumer-grade hardware, potentially accelerating the adoption of tailored AI solutions across industries. This article is accompanied by a conference presentation given by Legare Kerrison and Cedric Clyburn at WeAreDevelopers World Congress 2024, which can be viewed below.
What are some of the limitations of LLMs?
Despite their impressive capabilities, current LLMs face several critical limitations that hinder their effectiveness in specialized domains:
- Knowledge cut-off: Models are constrained by their training data, often leading to outdated information.
- Lack of transparency: It’s often unclear how these models arrive at their conclusions, which can lead to trust issues.
- False information: LLMs can generate convincing but incorrect responses.
- Lack of domain knowledge: Generalist models might not have the specific knowledge required for particular industries. Only a limited amount of enterprise knowledge is represented in LLMs.
- Explainability: Understanding why a model made a particular decision can be difficult.
These challenges highlight the need, and use cases, for more targeted approaches to better align your model to your expectations. When pre-trained and generalistic LLMs don’t meet your needs out of the box, what techniques can you use to improve their overall effectiveness, accuracy, and performance?
Techniques to enhance Generative AI models
To address the limitations of large language models, several key techniques have emerged:
- Pre-training and fine-tuning: While most companies don’t have the computational resources to engage in pre-training of a foundational model, fine-tuning typically involves taking an existing open-source model and conducting additional training for specific use cases. While effective, it's often resource-intensive, requiring significant computational power and time. The process usually entails forking the original model, which can make it challenging to incorporate improvements back into the main model version.
- Grounding (Retrieval Augmented Generation): This provides models with relevant external data to perform specific tasks. Unlike the previous methods, RAG doesn't actually improve the underlying model. Instead, it supplements the model's knowledge by retrieving and incorporating pertinent information at runtime. While this approach can enhance accuracy for specific queries, it doesn't inherently make the model more capable or knowledgeable.
Figure 1 depicts these enhancements techniques.
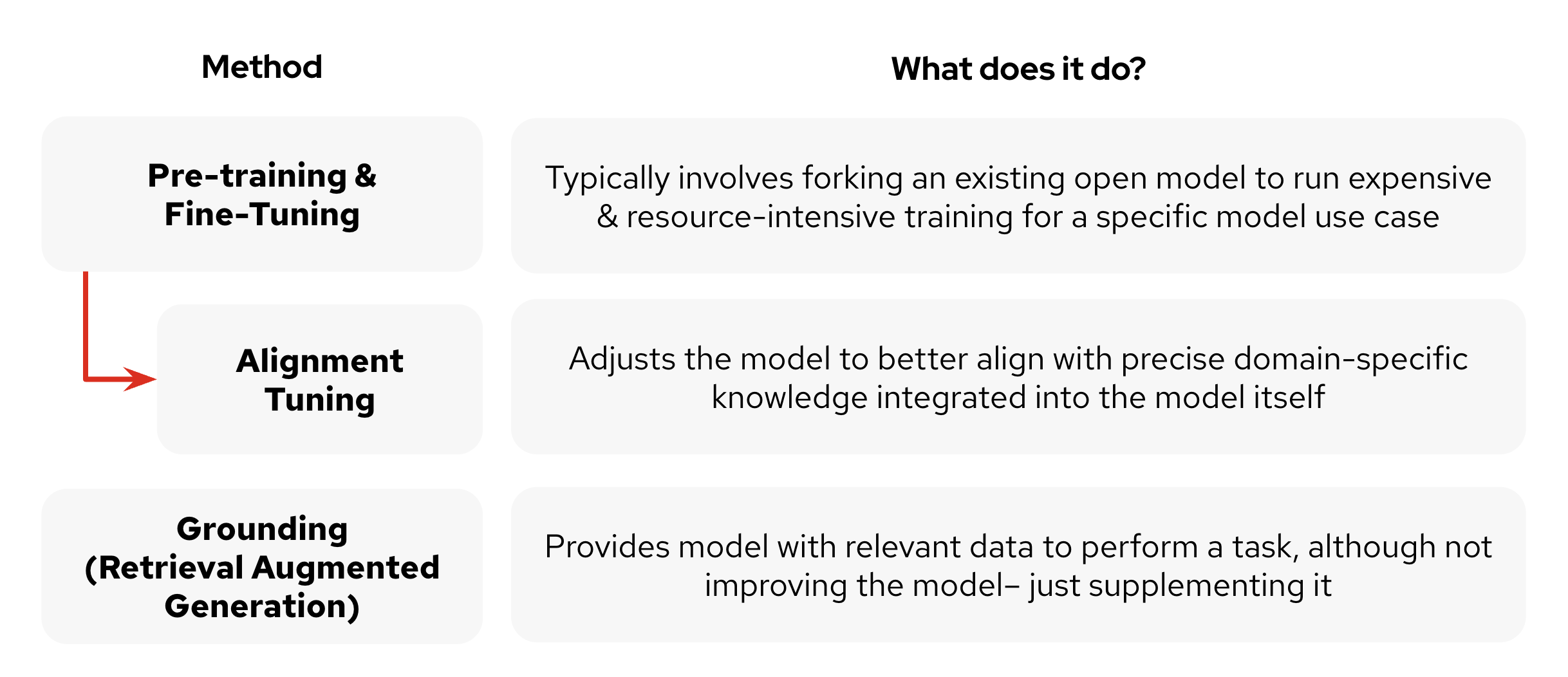
These techniques offer distinct advantages and can be particularly suited to different scenarios (or combined, in the case of fine-tuning and RAG). Fine-tuning excels at task-specific optimization, but traditionally at higher resource cost. RAG offers flexibility and up-to-date information, but requires an efficient pipeline and is simply supplementing the base model with information, not improving it.
Case study: Your foundation model’s impact on cost
Regardless of the method used to enhance a model, the choice of your foundation model can significantly impact the overall cost, performance, and efficiency of your AI solution. In Maryam Ashoori, PhD at IBM Watson’s case study, she illustrates the implications your chosen base model has on cost. Say that you would like to select an LLM to generate 500-word meeting summaries for a company with 700 employees, assuming each employee attends 5, 30-minute meetings daily, with 3 employees in each meeting. If we were to have a 52B Parameter General Purpose LMM do this, it would cost $0.09 per summary, adding up to $105 a day and to $38,325 per year. If you instead fine-tuned a smaller 3B Parameter Model hosted on Watsonx.AI, it would cost you $0.0039996 per summary, for a total of $1,702.19 a year plus a one-time $1,152 model tuning cost, equaling $2,854 per year. This means that using the fine-tuned LLM came out to be 14x cheaper than using the Large General LLM, as shown in Figure 2.

Using InstructLab for accessible model fine-tuning
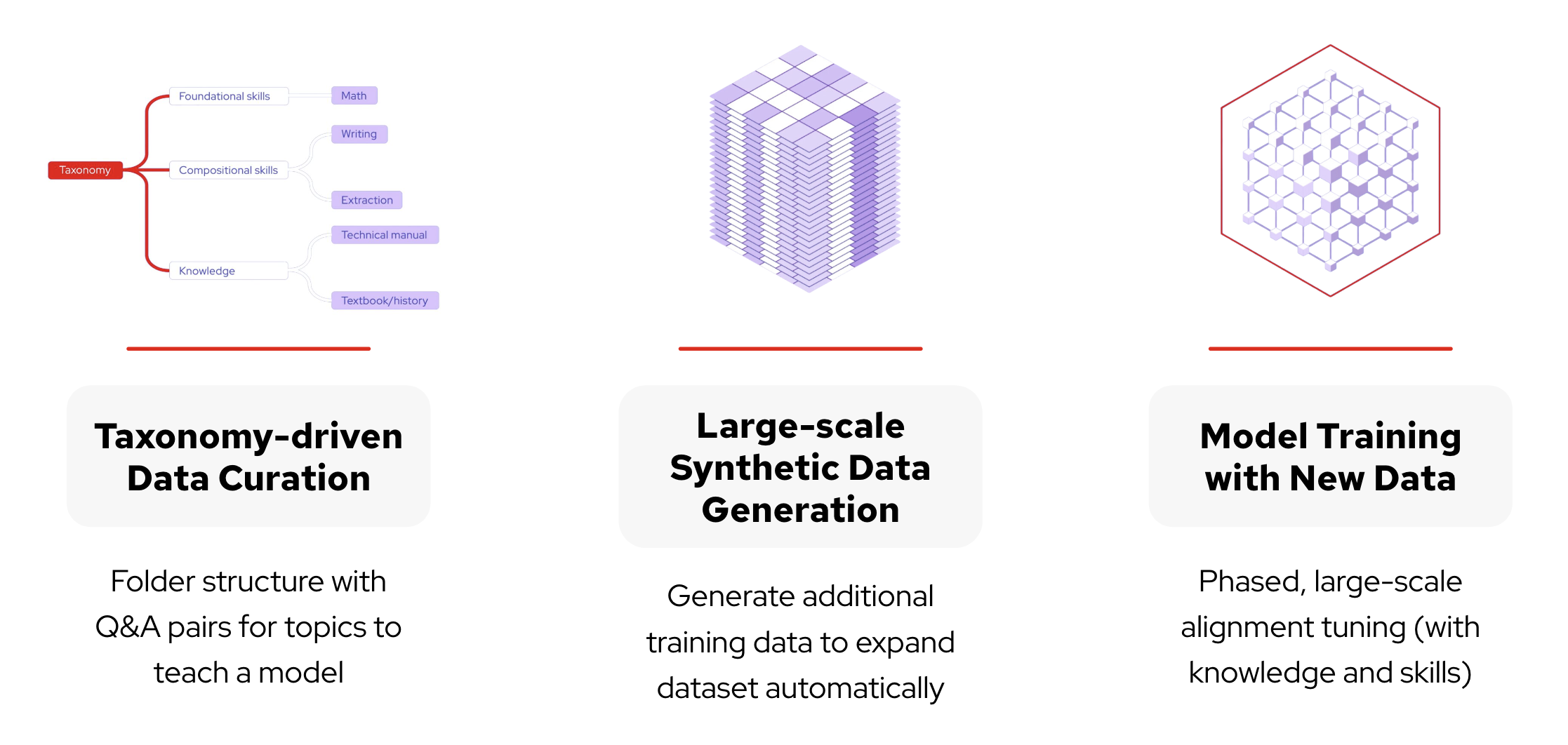
InstructLab provides a powerful framework for making LLM fine-tuning more accessible, and was designed to democratize the tuning and development of models for those without a data science background. InstructLab’s process is akin to having a teacher and a critic model working together to train the AI, ensuring the model is tailored to your specific domain, improving accuracy and relevance. This is possible through several key components, detailed in Figure 3:
- Taxonomy-driven data curation: The project organizes skills and knowledge into a structured folder-style directory, which helps identify and address specific gaps in the model’s capabilities.
- Large-scale synthetic data generation: Based on the initial user-defined examples, InstructLab creates additional diverse and high-quality training data.
- Multi-phase training: The new knowledge and skills are incorporated into the data in layered phases.
Once an individual has trained a model for their specific use case, they can then have their training data integrated with Instructlab’s community model through a pull request triage system. This open source methodology enables all to have a say in the future of model contributions and development, fostering a collaborative environment where diverse expertise and perspectives can shape AI development.
Conclusion
As AI continues to evolve, techniques like InstructLab are bridging the gap between cutting-edge AI research and practical, enterprise-ready applications. By making LLM tuning more accessible to individual users and organizations, we can overcome some of the limitations around models and create more accurate, reliable, and specialized AI solutions.
We believe the future of AI is collaborative and open. Whether you’re fine-tuning your own model or contributing to a shared community model that others can use, you’re helping to democratize AI. To get started with InstructLab, check out the GitHub repository for installation instructions on your system, and follow InstructLab on X and LinkedIn for updates about the project!
